In this tutorial, we are going to learn how to scrape websites with Rust. This tutorial will give you a basic idea of how to get information from a website using Rust. We are just going to scrape a single web page. Following links on the page and dealing with javascript is beyond the scope of this tutorial.
My GitHub repository containing the completed project can be found here: https://github.com/tmsdev82/rust-webscrape-tutorial.
Contents
What is web scraping?
Web scraping is an activity where a program gathers data from websites in an automated way. The program selects specific HTML tags in the page, that we have determined contain information we need. For example, the program can go to news sites, gather the content of articles based on specific keywords in the titles (H1, H2, etc tags) of those articles. This program can then analyze the data further to inform decisions. People often use information in news articles as signals for algorithmic trading. Because news articles describe significant events that could impact companies.
Web scraping programs also often use social media sites as sources for scraping and analysis. For example, to determine people’s feelings about a certain subject.
We are going to write a program that navigates to news sites, downloads the HTML pages, and then takes information from those pages. Once we have the information we will write that data to a file.
Prerequisites
A working Rust installation and some knowledge of Rust programming are required to follow this tutorial.
Set up the web scrape with Rust project
Let’s first create the project using cargo: cargo new rust-web-scrape-tutorial.
For this tutorial, we will be looking at the scraper crate to extract information from HTML. The complete list of crates we will use:
- tokio: An event-driven, non-blocking I/O platform for writing asynchronous I/O backed applications.
- reqwest: higher level HTTP client library.
- regex: An implementation of regular expressions for Rust. This implementation uses finite automata and guarantees linear time matching on all inputs.
- scraper: HTML parsing and querying with CSS selectors.
- serde: A generic serialization/deserialization framework.
- serde_json: A JSON serialization file format.
- chrono: Date and time library for Rust.
The reqwest and scraper crates are the only crates we need to scrape websites with Rust, the rest are used for data cleaning and saving and things like that.
Let’s open the Cargo.toml file and add all these dependencies:
[package]
name = "rust-web-scrape-tutorial"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
tokio = { version= "1", features = ["full"] }
reqwest = "0.11.7"
regex = "1"
scraper = "0.12.0"
serde = { version = "1.0", features = ["derive"]}
serde_json = "1.0"
chrono = "0.4"
Downloading HTML
Our first step in the process to scrape websites with Rust is to download an HTML page. Then our program can pick apart that HTML page to get specific pieces of information.
To download an HTML page our program needs a client for going to the web address. This is where we will use the reqwest library.
Configure the HTTP client object
Let’s put constructing the HTTP client in a separate file called utils.rs, let’s create it in the same directory as main.rs is located in:
use reqwest::Client;
static APP_USER_AGENT: &str = concat!(env!("CARGO_PKG_NAME"), "/", env!("CARGO_PKG_VERSION"));
pub fn get_client() -> Client {
let client = Client::builder()
.user_agent(APP_USER_AGENT)
.build()
.unwrap();
client
}
Here we use the Client::builder() for the reqwest library to build a client object. We use a static &str built from the package name and package version as the user agent name. This is a way for websites to identify our HTTP client. Even though it is not strictly necessary for many websites to have it, it is good practice to set an agent name.
Use the client to download a page
With the reqwest client object it becomes very easy to retrieve an HTML page located at a given URL. Let’s update main.rs with code to get a page from finance.yahoo.com:
use reqwest::StatusCode;
mod utils;
#[tokio::main]
async fn main() {
let client = utils::get_client();
let url = "https://finance.yahoo.com";
let result = client.get(url).send().await.unwrap();
let raw_html = match result.status() {
StatusCode::OK => result.text().await.unwrap(),
_ => panic!("Something went wrong"),
};
println!("HTML: {}", raw_html);
}
Let’s go through the important lines. First, we pull StatusCode into scope for determining the response status from our HTTP request later. Then, we also need out utils module, of course.
On line 5 we initiate the tokio async runtime: [tokio::main]. Doing this will allow us to use async functions which we will use for making HTTP requests.
Next, on line 7 we create an instance of the Client object using the function we wrote earlier. Then on line 9, we use the client to send a GET request to the yahoo finance URL: let result = client.get(url).send().await.unwrap();. We have to use await here because it is an asynchronous operation. This function returns a Response object as a result. This is the response the yahoo finance website server sends back to us.
With lines 11 through 14, we check to see if the status code was OK or if we got an error. In the case of an OK status code, we retrieve the text as String in the response by calling the text() function. This text contains the raw HTML for the web page we requested.
Finally, we print the raw HTML on line 16.
Running the program should result in a lot of text being printed to the terminal. We are getting somewhere. However, raw HTML is pretty useless. So, let’s look at how we can get useful information from this HMTL using the scrape crate.
Scrape useful information from websites with Rust
In this section, we are going to get some useful information from the raw HTML that our program downloads every time we run it. In this case, let’s get the article headlines from the yahoo finance front page.
We do this by telling the program to search for specific HTML elements that contain the information we want. Before we can do that, we have to figure out where these elements with useful information are located in the first place.
How to find the elements containing information on a page
One way we can do this is to open the page in our web browser, and then open the developer tools. On mac systems the hotkey for this is ALT+COMMAND+i on windows it is CTRL+SHIFT+i.
It will look something like this:
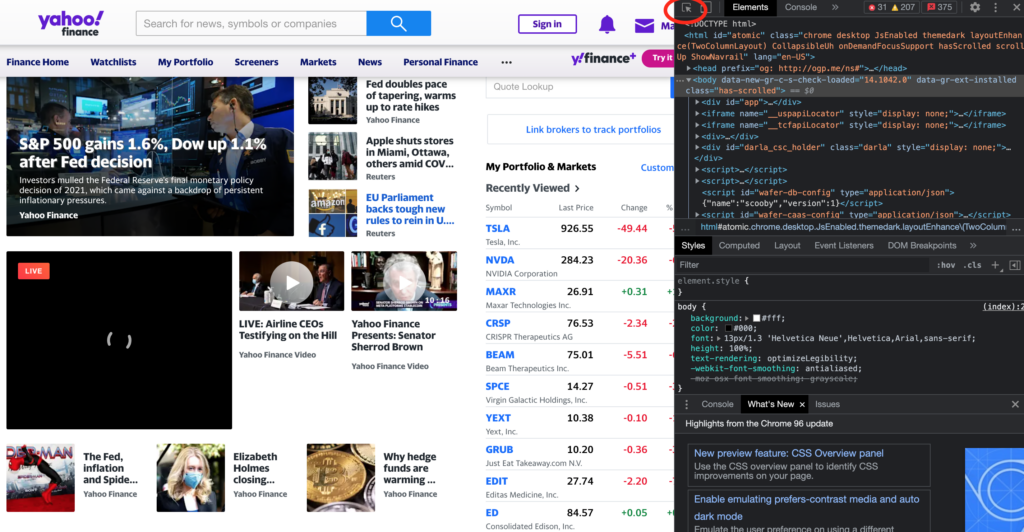
Let’s scroll down to where the main articles are and use the “select elements” tool (top left corner of the dev tools pane, circled in red), and click on an article or article headline to move to see its source HTML in the right pane.
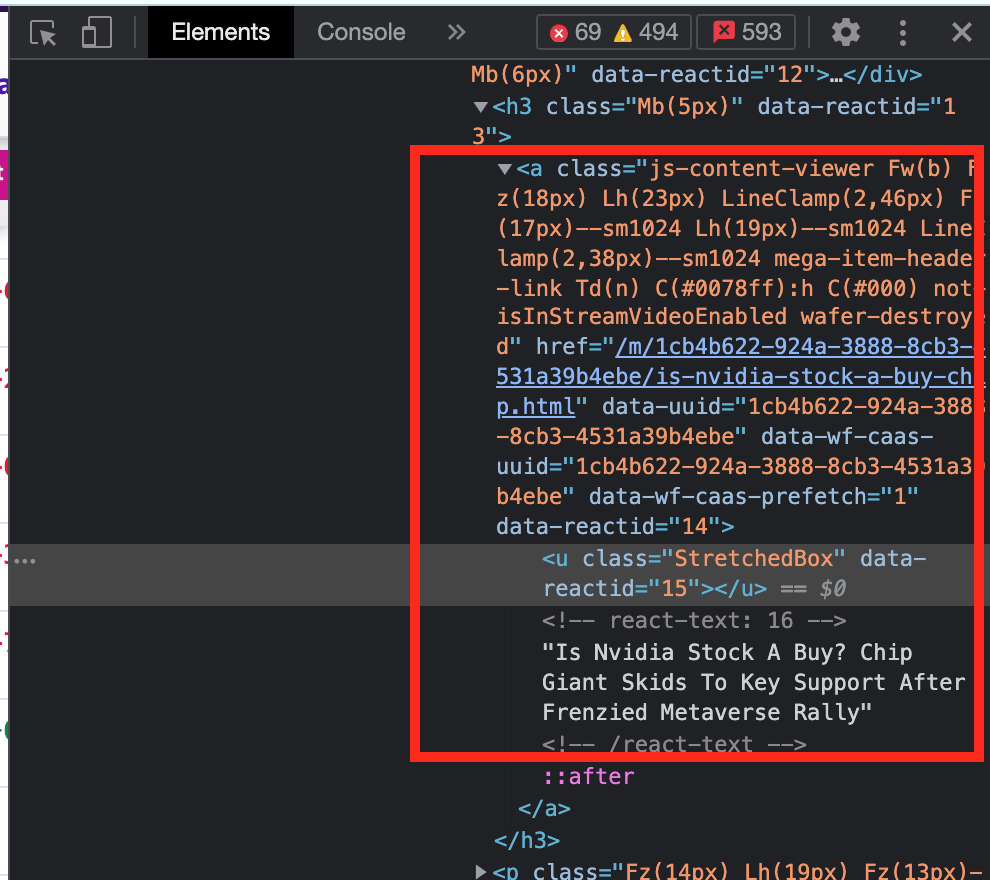
When clicking on an article, likely we will select the <u class="StretchedBox" ... element. Now, this article block is a clickable element so that suggests the whole thing is a link or <a> tag. If we look at the <u> element’s parent, we can see the start of the <a> tag, which also contains a relevant-looking link in the href attribute.
Let’s use this <a> tag as the element to select for. However, we have to be careful. Because we don’t want to select just any <a> tag on the page, there are likely many we don’t need, we should narrow it down a bit more. Let’s also use one of the CSS-style classes. In this case, we can try the js-content-viewer and see if that is specific enough.
Using scrape and selectors
Now that we have discovered more or less where the article titles are located we can use the scrape crate to extract this information. Let’s get some items from the scrape crate into scope:
use reqwest::StatusCode;
use scraper::{Html, Selector};
Then we can use Html to load the raw HTML and create an instance of that object. We will replace the println!() part at the end of our program with loading the raw HTML: let document = Html::parse_document(&raw_html);.
Scrape using <a> tag and class selector
Next, let’s create a selector instance for the a tag and the specific class we found earlier: let selector = Selector::parse("a.js-content-viewer").unwrap();. The first part of the string, the a, indicates the tag that should be selected for and then the dot . means that what comes after it is a class.
We will now use this selector to select all appropriate elements, we can then loop through this list of elements and print some information to the terminal. For convenience here is the full code listing so far:
use reqwest::StatusCode;
use scraper::{Html, Selector};
mod utils;
#[tokio::main]
async fn main() {
let client = utils::get_client();
let url = "https://finance.yahoo.com";
let result = client.get(url).send().await.unwrap();
let raw_html = match result.status() {
StatusCode::OK => result.text().await.unwrap(),
_ => panic!("Something went wrong"),
};
let document = Html::parse_document(&raw_html);
let article_selector = Selector::parse("a.js-content-viewer").unwrap();
for element in document.select(&article_selector) {
let inner = element.inner_html().to_string();
let href = match element.value().attr("href") {
Some(target_url) => target_url,
_ => "no url found",
};
println!("Title: {}", &inner);
println!("Link: {}", &href);
}
}
Our loop through the selected elements starts on line 20 where we pass a reference to our Selector instance to the select() function on the parsed document. This will produce a list of ElementRef instances if any elements are found that match the criteria of the selector object.
In the loop, we get the element’s inner HTML with inner_html() on line 21. This function call results in a String containing the HTML that is between the element’s opening and closing tags.
Next, on line 22 we grab the href attribute with .value().attr("href"). Our code uses match here to make sure it can deal with errors in case we are processing an element that doesn’t have the href attribute for some reason.
On the last lines of the loop, we output the inner HTML value and the href to the terminal.
When we run the program again we see that we still get too much text output in the for of HTML. While some don’t look as bad. However, we need to clean this data before it becomes useful:
Title: <div tabindex="-1" data-reactid="134" class="Pos(r) C($primaryColor) C($finDarkLinkHover):h Ovy(h) O(n):f"><img width="95" src="https://s.yimg.com/uu/api/res/1.2/hdb7wPshq6ZA4weOB7FG.A--~B/Zmk9c3RyaW07aD0xMzA7dz0xMzA7YXBwaWQ9eXRhY2h5b24-/https://s.yimg.com/os/creatr-uploaded-images/2021-12/e73e02c0-5e9d-11ec-9bbb-a6cb21b13035.cf.jpg" alt="Ray Dalio: Any war with China is 'likely to be around Taiwan'" data-reactid="135" class="D(ib) Mend(16px) Mend(12px)--md1100 Fl(start) Trs($ntkLeadImgFilterTrans) nedImage:h_Op(0.9) nedImage:h_Fill(ntkImgFilterHover) Fill(ntkLeadImgFilter) Bdrs(2px)" height="95"><div data-reactid="136" class="W(90%) M(0) Pt(10px)"><h3 data-reactid="137" class="Fz(14px)--md1100 Lh(16px)--md1100 Fw(b) Fz(16px) Lh(19px) LineClamp(3,60px) Va(m) Tov(e)">Ray Dalio: Any war with China is 'likely to be around Taiwan'</h3><p class="Fz(xs) C($tertiaryColor) Lh(14px) Mt(5px)" data-reactid="138">Yahoo Finance</p></div></div> Link: https://finance.yahoo.com/news/ray-dalio-any-war-with-china-is-likely-to-be-around-taiwan-193447918.html Title: <u class="StretchedBox" data-reactid="15"></u><!-- react-text: 16 -->3 Stocks That Are Flirting With a Bottom; Analysts Say ‘Buy’<!-- /react-text --> Link: /news/3-stocks-flirting-bottom-analysts-163921693.html Title: <u class="StretchedBox" data-reactid="32"></u><!-- react-text: 33 -->Dollar Will Hit Zero With Bitcoin Below $40K In 2022, Crypto CEO Says<!-- /react-text --> Link: /m/1d6fc20a-d902-3e9e-86dc-fd1f8bd9a097/dollar-will-hit-zero-with.html Title: <u class="StretchedBox" data-reactid="52"></u><!-- react-text: 53 -->Despite the big plunge, Cathie Wood sees her plan returning 40% annually in the next 5 years — here are Ark Invest’s latest buys<!-- /react-text --> Link: /news/despite-big-plunge-cathie-wood-173500607.html Title: <u class="StretchedBox" data-reactid="72"></u><!-- react-text: 73 -->These are the types of companies Warren Buffett says you should invest in during times of inflation<!-- /react-text --> Link: /m/f46d6122-0327-3b15-9407-ba52aaa7867f/these-are-the-types-of.html
Clean up data using header tag selectors
If we look carefully, the ones with all the clutter have the title text surrounded by header tags like h2 and h3, so let’s create selectors for those and use them to clean up this data a bit more.
So, let’s add the creation of these new selector instances below the selector we already had:
let document = Html::parse_document(&raw_html);
let article_selector = Selector::parse("a.js-content-viewer").unwrap();
let h2select = Selector::parse("h2").unwrap();
let h3select = Selector::parse("h3").unwrap();
Next, we can use them in the loop:
for element in document.select(&article_selector) {
let inner = element.inner_html().to_string();
let mut h2el = element.select(&h2select);
let mut h3el = element.select(&h3select);
let href = match element.value().attr("href") {
Some(target_url) => target_url,
_ => "no url found",
};
match h2el.next() {
Some(elref) => {
println!("H2: {}", &elref.inner_html().to_string());
println!("Link: {}", &href);
continue;
}
_ => {}
}
match h3el.next() {
Some(elref) => {
println!("H3: {}", &elref.inner_html().to_string());
println!("Link: {}", &href);
continue;
}
_ => {}
}
println!("Title: {}", &inner);
println!("Link: {}", &href);
}
Here we call the select() function on the element object and pass our header selector objects on lines 24 and 25. Then we call .next() on each of these Select object instances, on lines 32 and 41, to get the first element that matches the criteria. We are assuming that there is only one.
We use match to take care of situations when there is no header element found. If we find something we print the result and then make the loop continue to the next element.
Let’s run the program again and look at the results:
Link: https://finance.yahoo.com/news/stock-market-news-live-updates-december-17-2021-231504646.html H2: Stock futures steady after sell-off in tech shares Link: https://finance.yahoo.com/news/stock-market-news-live-updates-december-17-2021-231504646.html H3: Nasdaq closes down 2.5% amid tech sell-off Link: https://finance.yahoo.com/news/stock-market-news-live-updates-december-14-2021-232903478.html H3: Rivian to build $5 billion plant in Georgia, posts quarterly loss Link: https://finance.yahoo.com/news/ev-startup-rivian-build-plant-212157791.html H3: Kellogg reaches another tentative deal with union: Omaha union pres Link: https://finance.yahoo.com/news/kellogg-reaches-another-tentative-deal-212114531.html H3: Market recap: Thursday, Dec. 16 Link: https://finance.yahoo.com/video/market-recap-thursday-dec-16-225727051.html H3: Earnings: Rivian misses estimates Link: https://finance.yahoo.com/video/earnings-rivian-misses-estimates-225351189.html H3: What Biden left undone in 2021 Link: https://finance.yahoo.com/news/what-biden-left-undone-in-2021-195601863.html H3: Bitcoin, crypto boosted by Fed relief rally Link: https://finance.yahoo.com/news/bitcoin-crypto-boosted-by-relief-rally-as-investors-shrug-off-hawkish-fed-pivot-154950029.html H3: Ray Dalio: Any war with China is 'likely to be around Taiwan' Link: https://finance.yahoo.com/news/ray-dalio-any-war-with-china-is-likely-to-be-around-taiwan-193447918.html Title: <u data-reactid="15" class="StretchedBox"></u><!-- react-text: 16 -->3 Stocks That Are Flirting With a Bottom; Analysts Say ‘Buy’<!-- /react-text --> Link: /news/3-stocks-flirting-bottom-analysts-163921693.html Title: <u data-reactid="35" class="StretchedBox"></u><!-- react-text: 36 -->AT&T Stock Has Fallen to a Multi-Decade Low. Why It Could Be an Opportune Time to Buy.<!-- /react-text --> Link: /m/59ad6d72-787e-3b24-be1f-4b7d2ac7b337/at-t-stock-has-fallen-to-a.html Title: <u data-reactid="55" class="StretchedBox"></u><!-- react-text: 56 -->These are the types of companies Warren Buffett says you should invest in during times of inflation<!-- /react-text --> Link: /m/f46d6122-0327-3b15-9407-ba52aaa7867f/these-are-the-types-of.html Title: <u class="StretchedBox" data-reactid="75"></u><!-- react-text: 76 -->My daughter, 29, will inherit a ‘substantial sum’ from her late grandfather. But my husband maintains a tight grip on her trust.<!-- /react-text --> Link: /m/83e1e43e-5e5c-3889-9d60-ddaa92e0fc5f/my-daughter-29-will-inherit.html
The entries for the header elements are clean, with no other HTML elements. However, we are still left with entries that have <!-react-text: 76 --> and the like. We can clean these up using regular expressions.
Using regex to select a sub string
In this section, we are going to do the final data cleaning using regular expressions with the regex crate. So, let’s first get the relevant item into scope:
use regex::Regex;
use reqwest::StatusCode;
use scraper::{Html, Selector};
mod utils;
Next, let’s implement a regex for selecting the text we want, and one for cleaning up the selection. We will put them under the element selectors:
let article_selector = Selector::parse("a.js-content-viewer").unwrap();
let h2select = Selector::parse("h2").unwrap();
let h3select = Selector::parse("h3").unwrap();
let get_text_re = Regex::new(r"->.*<").unwrap();
let find_replace_re = Regex::new(r"[-><]").unwrap();
So, here on line 22, we have a regex that gets anything matching -> then any number of characters with .* ending on <. Then need a regex to remove the -> and < parts from the text we extract, so we create a regex for that on line 23.
Let’s use these regular expressions after the parts with the headers. Replace the println!() bits at the bottom of the loop:
match get_text_re.captures_iter(&inner).next() {
Some(cap) => {
let replaced = find_replace_re.replace_all(&cap[0], "");
println!("Regex: {}", &replaced);
println!("Link: {}", &href);
}
_ => {
println!("Nothing found");
}
}
Here we get the first match for the regex get_text_re using .next(), we use match to deal with any errors or empty matches. Then we use the other regex, find_replace_re, to find and replace the parts of the extracted text we do not need. Finally, we print the text we found together with the href we found earlier, just like what we did with the header tags.
Let’s run the program now to see how the results look:
Nothing found H2: Stock futures steady after sell-off in tech shares Link: https://finance.yahoo.com/news/stock-market-news-live-updates-december-17-2021-231504646.html H3: Clampdown on products from China's Xinjiang passes Congress Link: https://finance.yahoo.com/news/bill-clamp-down-products-chinas-181758173.html H3: Rivian to build $5 billion plant in Georgia, posts quarterly loss Link: https://finance.yahoo.com/news/ev-startup-rivian-build-plant-212157791.html H3: The worst company of the year Link: https://finance.yahoo.com/news/meta-facebook-worst-company-of-the-year-yahoo-finance-165345819.html H3: FedEx stock rises after beating earnings estimates Link: https://finance.yahoo.com/video/fedex-stock-rises-beating-earnings-231353637.html H3: Market recap: Thursday, Dec. 16 Link: https://finance.yahoo.com/video/market-recap-thursday-dec-16-225727051.html H3: What Biden left undone in 2021 Link: https://finance.yahoo.com/news/what-biden-left-undone-in-2021-195601863.html H3: Bitcoin, crypto boosted by Fed relief rally Link: https://finance.yahoo.com/news/bitcoin-crypto-boosted-by-relief-rally-as-investors-shrug-off-hawkish-fed-pivot-154950029.html H3: Ray Dalio: Any war with China is 'likely to be around Taiwan' Link: https://finance.yahoo.com/news/ray-dalio-any-war-with-china-is-likely-to-be-around-taiwan-193447918.html Regex: 3 Stocks That Are Flirting With a Bottom; Analysts Say ‘Buy’ Link: /news/3-stocks-flirting-bottom-analysts-163921693.html Regex: Despite the big plunge, Cathie Wood sees her plan returning 40% annually in the next 5 years — here are Ark Invest’s latest buys Link: /news/despite-big-plunge-cathie-wood-173500607.html Regex: These are the types of companies Warren Buffett says you should invest in during times of inflation Link: /m/f46d6122-0327-3b15-9407-ba52aaa7867f/these-are-the-types-of.html Regex: As U.S. inflation hits a 39year high, pros share 7 things to do with your money to help protect yourself from high inflation Link: /m/78ad5535-8494-32f5-9397-f5785b6e029f/as-u-s-inflation-hits-a.html
This looks good, there is no more unnecessary raw HTML.
Writing information we scrape from websites to a file with Rust
Now that we can scrape websites with Rust for information, let’s save this information to a file in JSON format for later use as an extra exercise.
Saving the raw HTML from the scrape to disk
First, let’s save the raw HTML to a file. So that, in the case where we might change or improve our information extraction, we can rerun the code on previously gathered data.
We have to add some things into scope:
use chrono;
use regex::Regex;
use reqwest::StatusCode;
use scraper::{Html, Selector};
use std::fs::File;
use std::io::Write;
For the file name of the raw HTML, let’s use a date and time string, and the source domain name for the page.
Let’s write a simple function for writing the raw HTML string to a file:
fn save_raw_html(raw_html: &str, domain_name: &str) {
let dt = chrono::Local::now();
let filename = format!("{}_{}.html", domain_name, dt.format("%Y-%m-%d_%H.%M.%S"));
let mut writer = File::create(&filename).unwrap();
write!(&mut writer, "{}", &raw_html).unwrap();
}
In this function, we use chrono to get the current local date and time on line 73, and then convert it to a formatted String. Then we create a writer object instance, and on the last line of the function we write the raw_html string to the file.
We also have to make some slight adjustments to the existing code:
async fn main() {
let client = utils::get_client();
let domain_name = "finance.yahoo.com";
let url = format!("https://{}", domain_name);
let result = client.get(url).send().await.unwrap();
let raw_html = match result.status() {
StatusCode::OK => result.text().await.unwrap(),
_ => panic!("Something went wrong"),
};
save_raw_html(&raw_html, domain_name);
Here we have split the domain name from the URL into separate variables so that we can use the domain name in the filename. Then we call our function to save the raw HTML to disk on line 22.
By the way, let’s add a rule to the .gitignore file to exclude HTML files. Or else we might clutter up our code repository with HTML files:
/target *.html
Our program now has the ability to save the downloaded HTML to disk. Let’s also implement functionality for saving the scraped data from the website to disk.
Saving scraped information as JSON to disk
In this last section, we are going to briefly go over how to save the scraped data as a JSON file. We are going to implement a data model that represents the data we want to gather, fill it with information from the website we scrape with Rust, and then serialize that data to disk using serde_json.
Implementing a data model
Let’s add a file called models.rs to the src directory of our project. Then, let’s define the structure for our data. The data structure is very simple for this tutorial:
use serde::Serialize;
#[derive(Debug, Serialize, Clone)]
pub struct ArticleData {
pub article_title: String,
pub url_link: String,
pub domain_name: String,
}
We use derive on the struct to add the ability to print the struct as debug information, to serialize the struct, and to clone the struct.
Turning scraped data into a list of object
Next, we will update main.rs so that the website data we scrape with our Rust program is stored in a list of ArticleData objects: let mut article_list: Vec<models::ArticleData> = Vec::new();
We can then push new ArticleData instances onto the list in the match blocks for the elements, for example:
match h2el.next() {
Some(elref) => {
let title = elref.inner_html().to_string();
println!("H2: {}", &title);
println!("Link: {}", &href);
article_list.push(models::ArticleData {
article_title: title,
url_link: href.to_string(),
domain_name: domain_name.to_string(),
});
continue;
}
_ => {}
}
As stated earlier, we simply create an instance of the ArticleData struct and push it onto the Vec. The full updated loop code is listed below:
let mut article_list: Vec<models::ArticleData> = Vec::new();
for element in document.select(&article_selector) {
let inner = element.inner_html().to_string();
let mut h2el = element.select(&h2select);
let mut h3el = element.select(&h3select);
let href = match element.value().attr("href") {
Some(target_url) => target_url,
_ => "no url found",
};
match h2el.next() {
Some(elref) => {
let title = elref.inner_html().to_string();
println!("H2: {}", &title);
println!("Link: {}", &href);
article_list.push(models::ArticleData {
article_title: title,
url_link: href.to_string(),
domain_name: domain_name.to_string(),
});
continue;
}
_ => {}
}
match h3el.next() {
Some(elref) => {
let title = elref.inner_html().to_string();
println!("H3: {}", &title);
println!("Link: {}", &href);
article_list.push(models::ArticleData {
article_title: title,
url_link: href.to_string(),
domain_name: domain_name.to_string(),
});
continue;
}
_ => {}
}
match get_text_re.captures_iter(&inner).next() {
Some(cap) => {
let replaced = find_replace_re.replace_all(&cap[0], "");
println!("Regex: {}", &replaced);
println!("Link: {}", &href);
article_list.push(models::ArticleData {
article_title: replaced.to_string(),
url_link: href.to_string(),
domain_name: domain_name.to_string(),
});
}
_ => {
println!("Nothing found");
}
}
}
println!("Number of articles titles scraped: {}", article_list.len());
Serializing data and saving as JSON
Now that we have a list of objects, we have data to save to disk. This last step, in this tutorial for how to scrape websites with Rust, is easy thanks to the serde crate for serializing data. Let’s write a function that encapsulates that functionality:
fn save_article_list(article_list: &Vec<models::ArticleData>, domain_name: &str) {
let dt = chrono::Local::now();
let filename = format!("{}_{}.json", domain_name, dt.format("%Y-%m-%d_%H.%M.%S"));
let mut writer = File::create(&filename).unwrap();
write!(
&mut writer,
"{}",
&serde_json::to_string(&article_list).unwrap()
)
.unwrap();
}
We use the same file naming style as with the raw HTML; a date/time part and the domain name. Then we create a write instance with File::create(), and finally, use serde_json::to_string to turn the Vec<models::ArticleData, article_list, into a string so it can be saved to disk.
After running the program now, we will end up with a new JSON file containing the data we scraped. Let’s not forget to put a new rule in our .gitignore:
/target *.html *.json
Conclusion
After going through this tutorial we have learned the basics of how to scrape websites with Rust. During this process, we learned how to find HTML elements to target with our scraping, and also how to clean up the data, and turn it into actual useful information.
We can use this knowledge as a basis for interesting applications that use news data to infer trends in the news, or quickly find interesting news about companies or other subjects we are interested in using an automated program. However, such things are beyond the scope of this basic tutorial.
My GitHub repository containing the completed project can be found here: https://github.com/tmsdev82/rust-webscrape-tutorial.
Please follow me on Twitter to get notified on new Rust programming and data gathering or analysis related articles:
Follow @tmdev82
Thanks a lot for your howto….
could you explane how to scrape data inside from “…”
for example the EUR Value from this page:
https://www.btc-echo.de/kurs/xrp/